On November 22, Robert Steimer from Bank Julius Baer once again organized the ERFA conference in Zurich, this time held by the Six Group. Only a small number of guests are invited to this mini-conference every year; this time, there were just below 20 automotive experts on site.
Some participants gave lectures at the event, including a guest lecture by Jörg Eichler, the chairman of the association “FOKUS“.
And of course I did not miss the opportunity to talk about one of my favorite topics: Design Pattern.

Me, giving my presentation. Don’t worry, the bottle of wine is not my snack for the talk.
Design Patterns in theory
If you want to create a new automation with Automic, there are usually several options available to do it. So you always have to decide what’s the best way to implement the requirement.
This is where design patterns help you.
The idea is, that you do not look for specific solutions to individual problems, but abstract problems on a generic requirement pattern and then look for solutions to those parent patterns.
Such a generic solution — a design pattern — can then be used for all similar problems to quickly find the best implementation.
So these are best practices for specific needs.
Alright?
Perfect. So I can wrap this up and be done with the article, right?
No, do not worry. Of course, I have also prepared an example that makes this abstract explanation a little more tangible.
A Practical Example for Design Patterns
Let’s look at Design Patterns with explain design patterns is pretty straightforward:
External files are delivered to a directory. Then they have to be loaded with an external program. Finally, all files are archived in the sub directory “done”.
A maximum of 10 files will be delivered per hour and each file must be loaded at the latest one hour after delivery. The loading does not have to happen in a specific order and can also run in parallel.
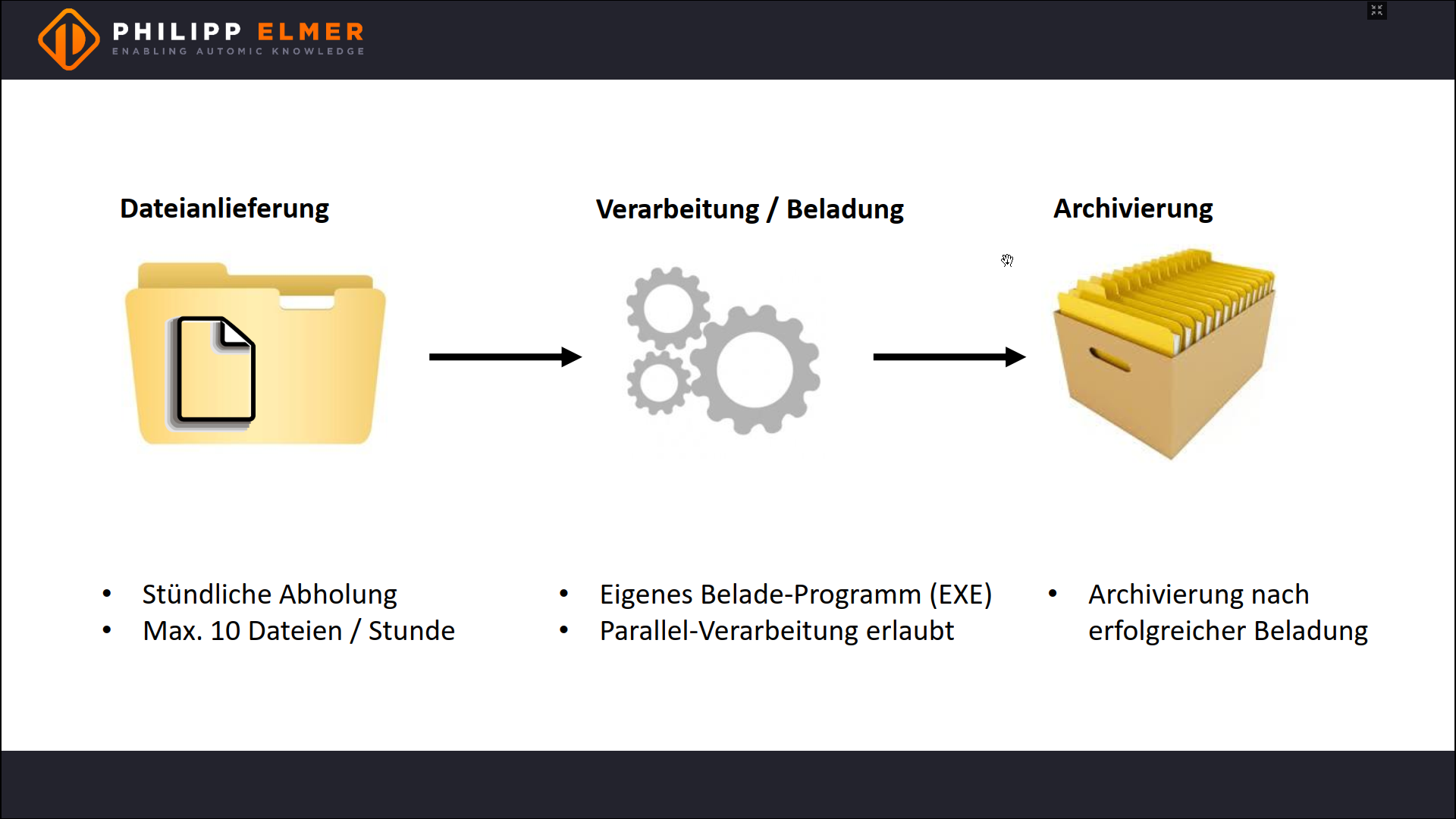
Simple Example of a Requirement
Everything considered, that’s a pretty simple requirement.
You probably already have a solution ready — or even several, as there are many ways to reach the goal.
In order to find a design pattern, we want to abstract the solution and for this we first have to make a fundamental distinction: should the files be processed individually or together?
More precisely, we have the following two options:
- Every hour, a job is triggered and in this job all files of the last hour are processed. Automic does the scheduling, the logic of execution is in the job.
- Every hour, a SCRI loop is triggered, which then triggers a workflow for each file. This workflow processes the file and then moves it to the archive. The complete logic lies here in Automic.
So we have two fundamentally different approaches and the difference between them is clear: the first one offers more performance when many files need to be processed, the second one is clearer, offers better reporting and more options for custom execution.
On an abstract level, the amount of files determines which variant is used. We can formulate a general rule from this:
Always process files one at a time, unless there are many files (for example, 10,000 files per hour, depending on the size of your system), so that performance suffers too much.
Of course, you still have to weigh in borderline cases, but with 10 files per hour the choice is pretty clear.
The Basic Design Pattern
To implement this solution, we first need a workflow that loads a file and then moves it to the “Done” directory.
The file name is given to the workflow via a promptset.
But what about all the other information? The agent, the directory paths and so on?
Or more general: How is the workflow configured?
There is a best practice for this. Configuration should be separated from the logic so that the logic is transportable. That’s why we use a VARA, for example a VARA.STATIC or a VARA.XML.
And a best practice has also established for how to pass the configuration on. The VARA is read out in the promptset, as it allows you to easily change the parameters ad-hoc — for reruns, single executions, of unit tests.
These considerations result in a first, very simple design pattern that can be used for many tasks.

A very generic Design Pattern I use for almost all automations.
How to Handle Sub Jobs
The next relevant step is dealing with sub-jobs. More specifically, how do subordinate jobs get the configuration parameters?
There are three possibilities here:
- The workflow forwards the parameters to the sub-jobs.
- The PromptSets of the sub-jobs access the configuration directly.
- The sub-jobs have their own configuration VARAs, which in turn reference the main configuration.
The best solution depends on the individual case, but the rule of thumb is: For simple, small workflows, choose variant 1. For complex requirements, the third option is the recommended solution because this allows you to separately test, develop, and transport the sub-jobs. Variant 2 can be used in cases that lie in between.
In practice, you would usually choose Variant 1 for simple requests like our example. I chose Variant 3 because it may be less familiar to you.
The result looks like the screenshot below.
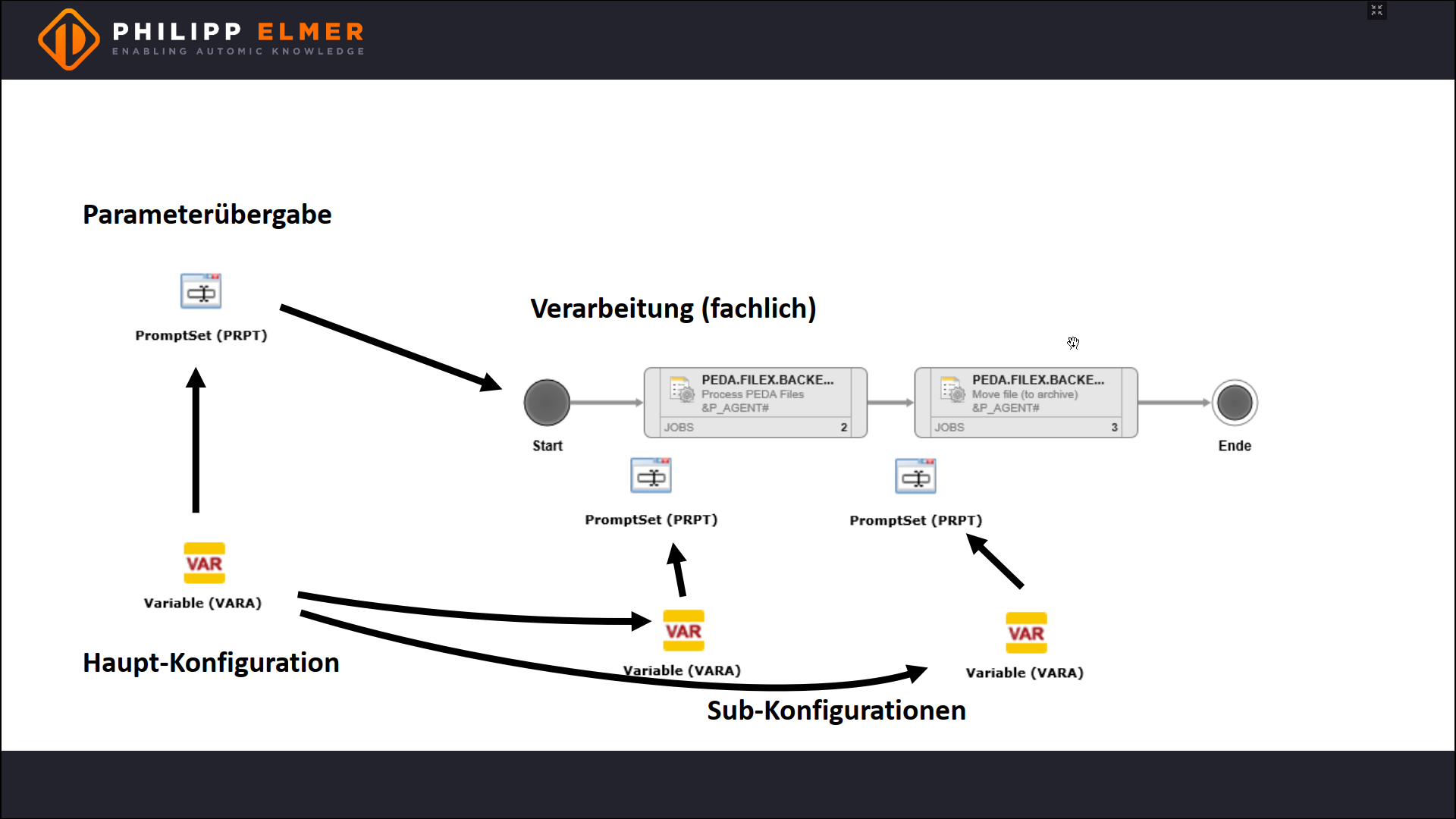
Design Pattern with a simple Workflow and Sub-Jobs.
How to Trigger the Workflows
The workflow should be started once for each file, so we need a script with ACTIVATE_UC_OBJECT. This passes the parameters from the PromptSet, i.e. the file name.
This is where another best practice comes into play: we group all workflow executions together in a job group. With this, we have some more options for control. We can for example regulate how many workflows are allowed to run in parallel.
Then we have to consider how the script reads the file system and triggers a workflow for each file. Again, there are many ways: PREP_PROCESS_FILELIST, VARA.FILELIST, EXEC or BACKEND.
Since we are looking for a design pattern, we first abstract the requirement. In a very abstract way, we want to consume external data and are looking for the best solution.
Put this way, there is a clear best practice with Automic: For consuming external data, we use a VARA object.
Now we need to loop over the VARA entries so the script can trigger the workflows. This can be done directly in the script itself, but here we choose the slightly clearer variant, namely a FOREACH workflow.
Why don’t we trigger the processing workflow directly in the FOREACH workflow? Because FOREACH workflows run sequentially, but we want to process the files in parallel.
Finally, we pack everything together into a master workflow.
You can see the result in the following graphic.
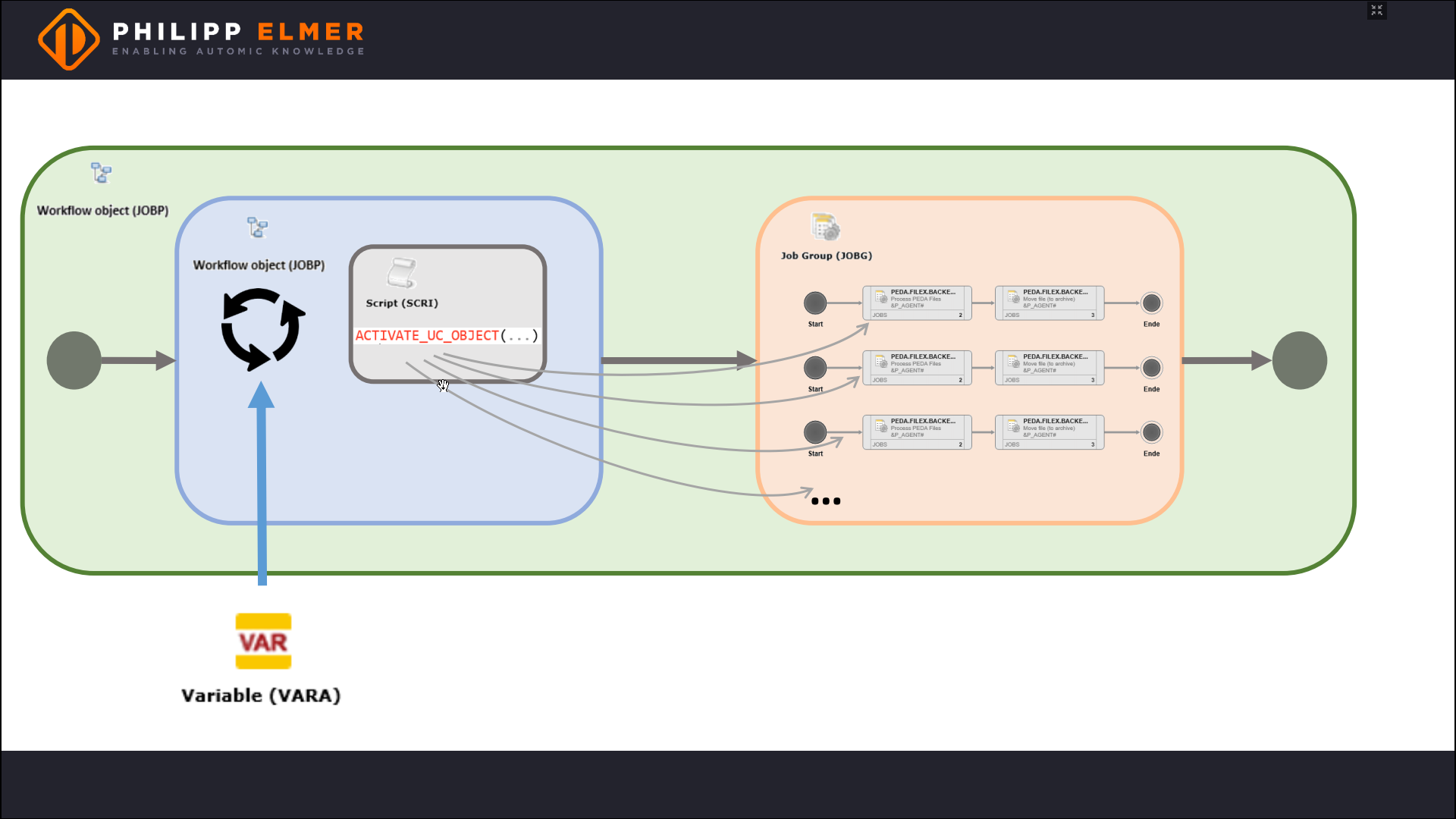
The complete Design Pattern
Final Thoughts about the Design Pattern
The last graphic shows the final result of our considerations.
As you see, we’ve solved the original request, but we’ve also created a template for a whole range of problems. We can use this pattern for any kind of parallel data processing.
Useful, right?
And from this pattern, we can quickly derive variants, for example for sequential instead of parallel data processing.
Similar solution templates can be found for all kinds of problems — and you can also create individual ones, especially for the tasks you often have to do.
I am thinking a lot about this topic, and I am currently considering launching a new workshop based about the topic “Best Ways to Automate with Automic”.
Would that be interesting for you? Do you have thoughts and ideas about this?
Let me know in the comments.