Am 22. November organisierte Robert Steimer von der Bank Julius Bär wieder einmal die ERFA Konferenz in Zürich, dieses Mal ausgetragen von der Six Group. Zu dieser Mini-Konferenz werden jedes Jahr nur wenige Gäste eingeladen, dieses Jahr waren knapp 20 Automic-Experten vor Ort.
Einige der Teilnehmer haben bei der Veranstaltung Vorträge gehalten, unter anderem gabe es einen Gastvortrag von Jörg Eichler, der Vorsitzende des Vereins „FOKUS“.
Und ich habe mir die Gelegenheit natürlich auch nicht nehmen lassen, mal wieder über eines meiner Lieblingsthemen zu reden: Design Pattern.

Ich bei meinem Vortrag. Keine Sorge, die Flasche Wein auf dem Tisch war nicht mein Proviant.
Design Patterns in der Theorie
Wenn Sie eine neue Automatisierung mit Automic erstellen wollen, stehen dafür meistens mehrere verschiedene Möglichkeiten zur Verfügung. Sie müssen sich also immer wieder entscheiden, wie Sie die Anforderung am besten umsetzen.
Dabei helfen Ihnen Design Pattern.
Die Idee dahinter ist, dass Sie nicht nach spezifischen Lösungen für einzelne Probleme suchen, sondern Probleme auf ein generisches Anforderungs-Muster abstrahieren und dann Lösungen für diese übergeordneten Muster suchen.
Eine solche generische Lösung, sprich ein Design Pattern, kann dann für alle ähnlichen Probleme verwendet werden, um schnell die beste Umsetzung zu finden.
Es sind also Best Practices für bestimmte Anforderungen.
Alles klar?
Dann kann ich den Blogartikel hier ja schon abschließen.
Nein, kein Sorge. Ich habe natürlich auch noch ein Beispiel vorbereitet, dass diese abstrakte Erklärung etwas greifbarer macht.
Design Patterns an einem praktischen Beispiel
Das Beispiel, an dem ich Design Patterns erläutere, ist erstmal ziemlich einfach:
Von extern werden Dateien in ein Verzeichnis angeliefert. Dann müssen sie mit einem externen Programm beladen werden. Zum Schluss werden alle Dateien ins Unterverzeichnis “done” archiviert.
Pro Stunde werden maximal 10 Dateien angeliefert und jede Datei muss spätestens eine Stunde nach der Anlieferung beladen werden. Die Beladung muss dabei nicht in einer bestimmten Reihenfolge ablaufen und kann auch parallel laufen.
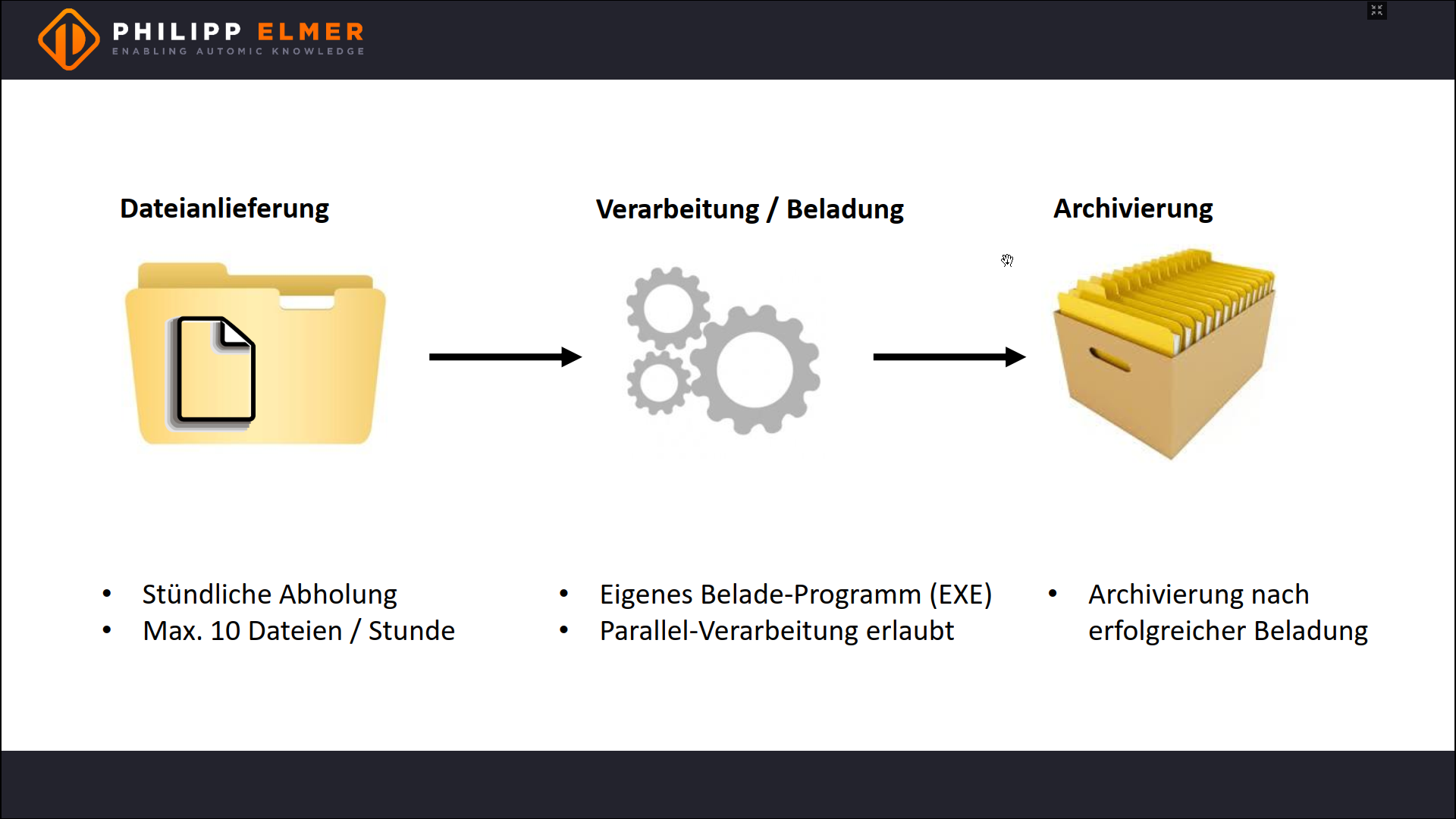
Einfaches Beispiel für eine Anforderung.
Alles in allem also eine recht einfache Anforderung.
Sie haben bestimmt auch schon eine Lösung dafür parat – oder sogar mehrere, denn es gibt hier viele Wege zum Ziel.
Um ein Design Pattern zu finden, wollen wir die Lösung abstrahieren und dafür gilt es zunächst eine grundsätzliche Unterscheidung zu treffen: Sollen die Dateien einzeln oder gemeinsam verarbeitet werden?
Genauer gesagt sind das die folgenden zwei Möglichkeiten:
- Jede Stunde wird ein Job getriggert und in diesem Job werden alle Dateien der letzten Stunde verarbeitet. Automic erledigt das Scheduling, die Logik der Ausführung steckt im Job.
- Jede Stunde wird ein SCRI-Loop gestartet, der für jede Datei einen Workflow triggert. Der Workflow verarbeitet die Datei und verschiebt sie anschließend ins Archiv. Die komplette Logik liegt hier in Automic.
Wir haben also zwei grundlegend verschiedene Lösungsansätze und der Unterschied zwischen ihnen ist auch klar: Die erste Variante bietet mehr Performance, wenn viele Dateien verarbeitet werden müssen, die zweite Variante ist übersichtlicher, bietet besseres Reporting und mehr Möglichkeiten zur individuellen Ausführung.
Auf einer abstrakten Ebene entscheidet vor allem die Menge an Dateien darüber, welche Variante zum Einsatz kommt. Wir können daraus eine allgemeine Regel formulieren:
Verarbeite Dateien immer einzeln, es sei denn es sind sehr viele Dateien (je nach Systemgröße zum Beispiel 10.000 Dateien pro Stunde), sodass die Performance darunter zu sehr leidet.
In Grenzfällen muss man natürlich trotzdem noch abwägen, bei 10 Dateien pro Stunde ist die Wahl aber ziemlich klar.
Das grundlegende Design Pattern
Um diese Lösung umzusetzen brauchen wir zunächst einen Workflow, der eine Datei belädt und dann ins Verzeichnis “Done” verschiebt.
Den Dateinamen erhält der Workflow über ein Promptset.
Aber was ist mit allen anderen Informationen? Der Agent, die Verzeichnispfade und so weiter?
Sprich: Wie wird der Workflow konfiguriert?
Dafür gibt es eine Best Practice. Konfiguration sollte von der Logik getrennt sein, damit die Logik gut transportierbar ist. Deshalb verwenden wir eine VARA, zum Beispiel eine VARA.STATIC oder eine VARA.XML.
Und auch zur Übergabe der Konfiguration hat sich eine Best Practice etabliert. Die VARA wird im Promptset ausgelesen, da man so die Parameter ad-hoc leicht ändern kann – zum Beispiel bei Reruns, bei Einzelausführungen oder für Unit-Tests.
Aus diesen Überlegungen ergibt sich ein erstes, sehr simples Design Pattern, das man so für viele Aufgaben benutzen kann.

Ein sehr generisches Design Pattern, das ich so fast für jede Automatisierung verwende.
Der Umgang mit Unterjobs
Der nächste relevante Schritt ist der Umgang mit Unter-Jobs. Genauer gesagt: Wie kommen untergeordnete Jobs an die Parameter?
Hier gibt es drei Möglichkeiten:
- Der Workflow gibt die Parameter an die Unterjobs weiter.
- Die PromptSets der Unter-Jobs greifen direkt auf die Konfiguration zu.
- Die Unter-Jobs haben eigene Konfigurations-VARAs, die ihrerseits auf die Haupt-Konfiguration referenzieren.
Was die beste Lösung ist, hängt vom Einzelfall ab, aber die Faustregel ist: Für einfache, kleine Workflows wählen Sie Variante 1. Bei komplexen Anforderungen ist die dritte Variante die empfohlene Lösung, weil man so die Unter-Jobs auch separat testen, entwickeln und transportieren kann. Variante 2 kann in Fällen zum Einsatz kommen, die dazwischen liegen.
In der Praxis wird man für eine einfache Anforderung wie in unserem Beispiel meistens Variante 1 wählen, ich habe hier aber Variante 3 gewählt, weil die Ihnen vielleicht weniger geläufig ist.
Das sieht dann aus, wie im folgenden Screenshot dargestellt.
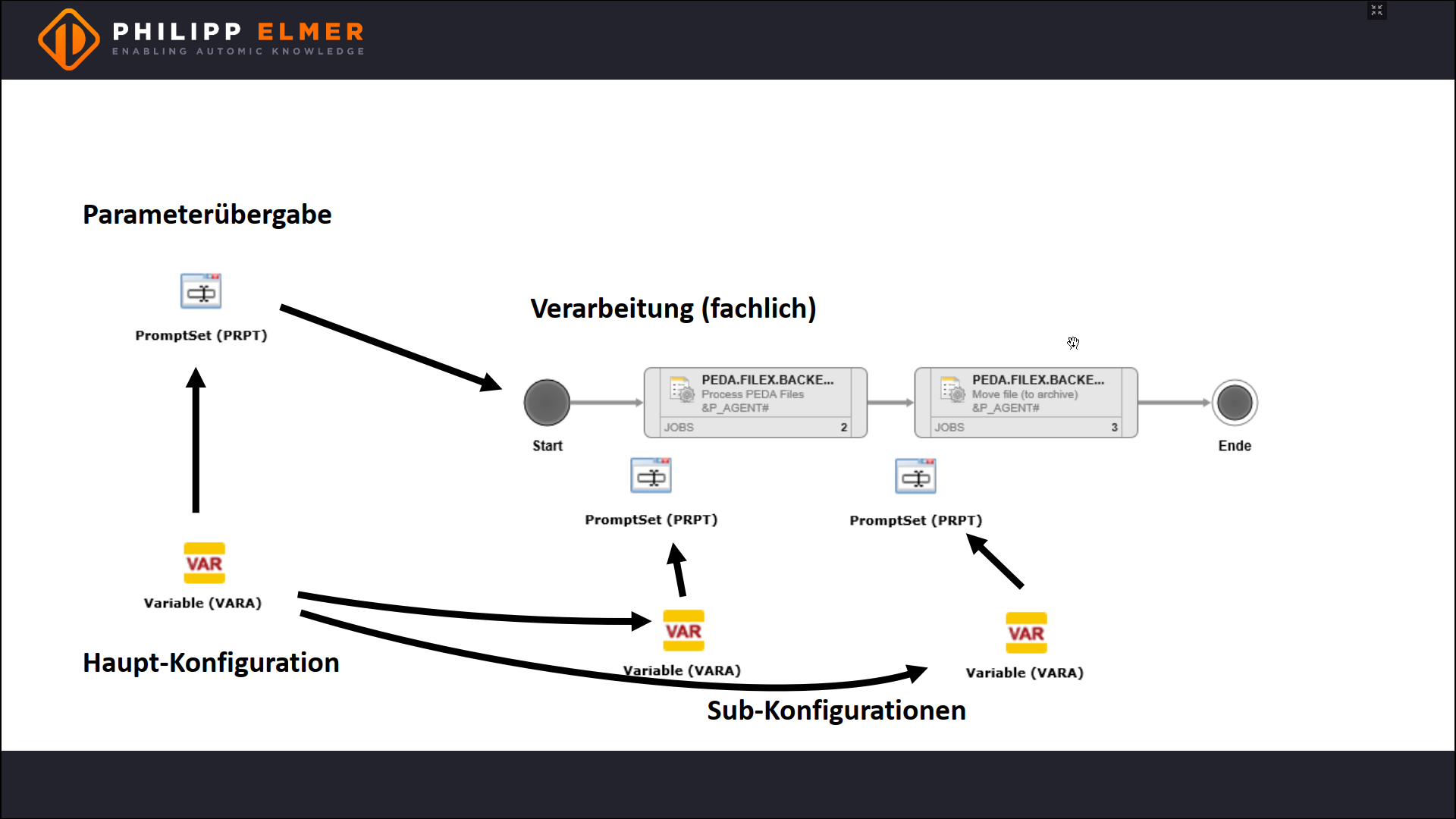
Design Pattern mit einfachem Workflow und Unter-Jobs.
Das Starten der Workflows
Der Workflow soll ja für jede Datei einmal gestartet werden, wir brauchen also ein Script mit ACTIVATE_UC_OBJECT. Dieses übergibt die Parameter aus dem PromptSet, also den Dateinamen.
Hier kommt eine weitere Best Practice ins Spiel: Wir fassen alle Workflow-Ausführungen in einer Jobgruppe zusammen. So können wir zum Beispiel auch regeln, wie viele Workflows maximal parallel laufen dürfen.
Anschließend müssen wir uns darum kümmern, wie das Script das Dateisystem liest und für jede Datei einen Workflow triggert. Auch hier gibt es mal wieder viele Wege: PREP_PROCESS_FILELIST, VARA.FILELIST, EXEC oder BACKEND.
Da wir nach einem Design Pattern suchen, abstrahieren wir zunächst die Anforderung. Ganz abstrakt wollen wir externe Daten konsumieren und suchen dafür die beste Lösung.
So formuliert gibt es mal wieder eine klare Best Practice bei Automic: Zum Konsumieren externer Daten verwenden wir ein VARA-Objekt.
Über die Einträge der VARA muss jetzt eine Schleife laufen, damit das Script die Workflows triggern kann. Das kann direkt im Script selbst geschehen, wir wählen hier aber die etwas übersichtlichere Variante, nämlich einen FOREACH-Workflow.
Warum triggern wir den Verarbeitungs-Workflow nicht direkt im FOREACH-Workflow? Weil FOREACH-Workflows sequentiell ablaufen, wir aber die Dateien parallel verarbeiten wollen.
Und schließlich packen wir alles zusammen noch in einen Master-Workflow.
Das Ergebnis sehen Sie in der folgenden Grafik.
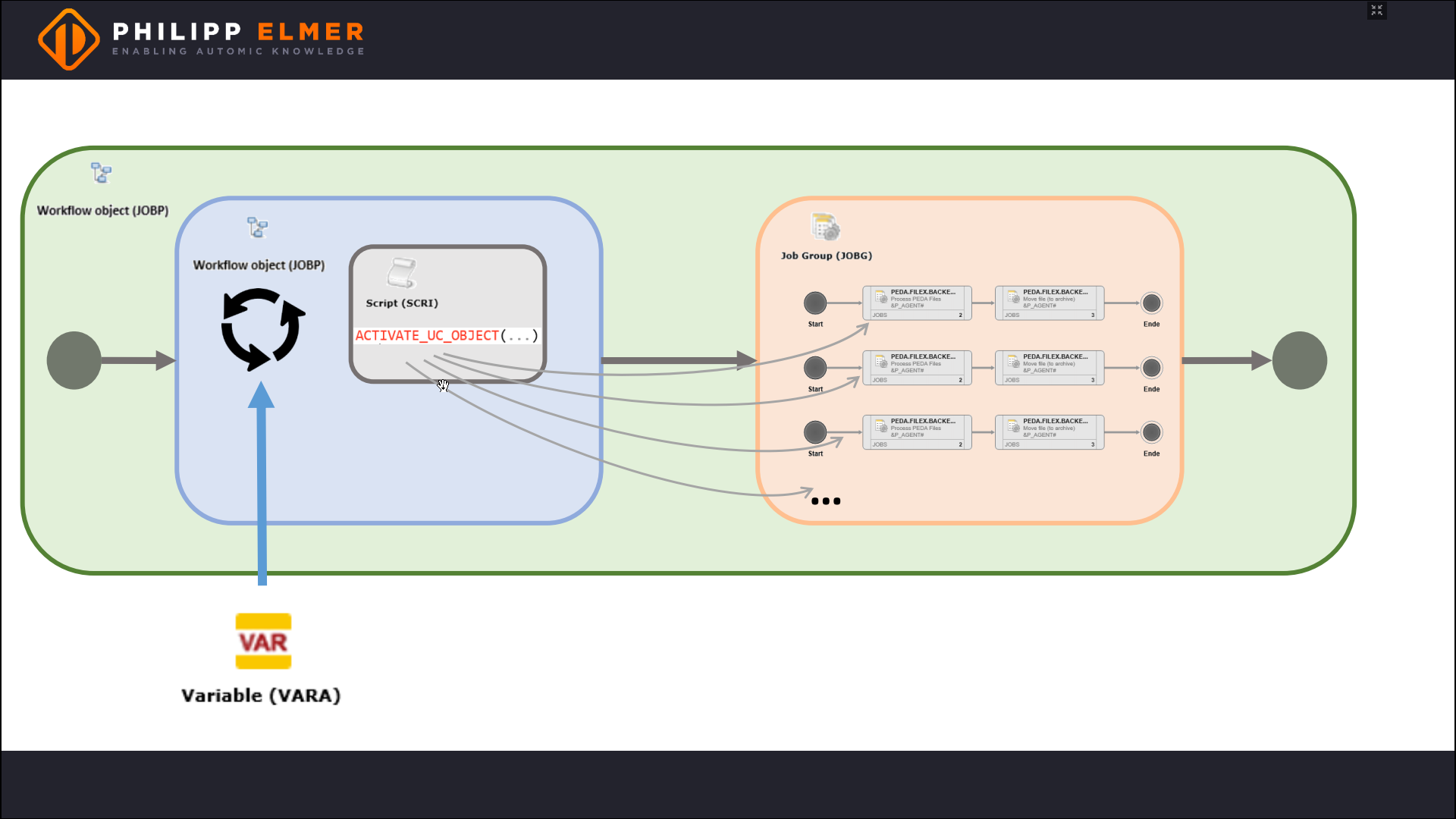
Das fertige Design Pattern
Abschließender Blick auf das Design Pattern
Die letzte Abbildung zeigt das finale Ergebnis unserer Überlegungen.
Und Sie sehen: Wir haben die ursprüngliche Anforderung gelöst, aber gleich eine Schablone für eine ganze Reihe von Problemen erstellt. Das Pattern können wir für jede Art der parallelen Datenverarbeitung verwenden.
Nützlich, oder?
Und von diesem Pattern aus lassen sich auch schnell neue Varianten ableiten, zum Beispiel für sequentielle statt parallele Verarbeitung der Daten.
Und ähnliche Lösungsschablonen lassen sich für alle möglichen Probleme finden und können auch sehr individuell sein.
Mich beschäftigt dieses Thema sehr und ich spiele derzeit mit dem Gedanken, einen neuen Workshop nach dem Motto “Wie automatisiert man mit Automic am besten?” zu entwerfen.
Wäre das für Sie interessant? Haben Sie Ideen und Vorstellungen dazu?
Lassen Sie es mich in den Kommentaren wissen.